Scalable Asymmetric Retrieval with Voyage AI Embeddings in Vespa¶
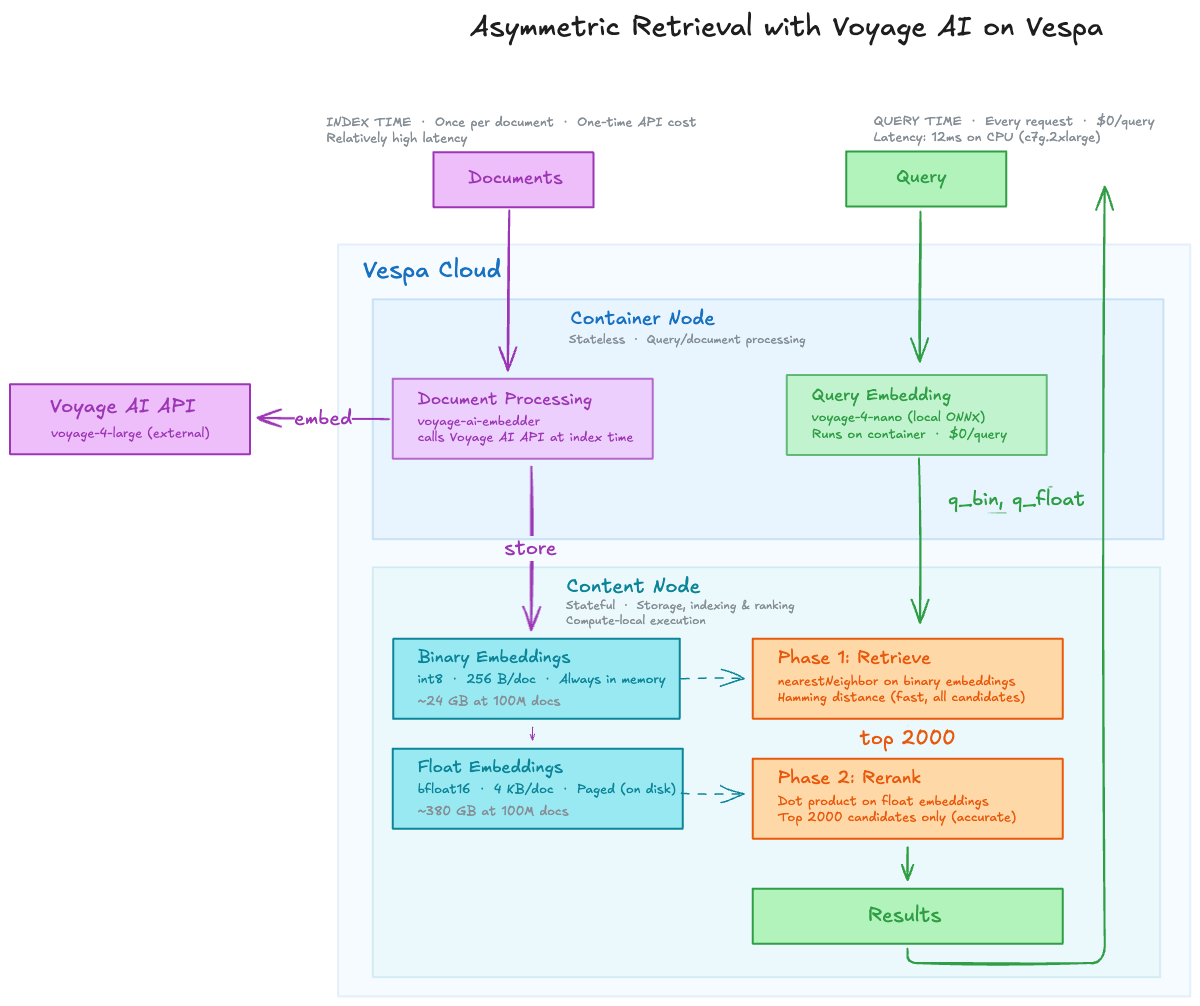
The Voyage 4 model family offers state-of-the-art embedding quality across a range of model sizes. Vespa recently added an integration to allow for seamless embedding through Voyage's API. This notebook demonstrates an asymmetric retrieval pattern, combining both this API-based integration, and a Vespa-local Open Source model:
- Indexing: Use
voyage-4-large(API-based, highest quality) to embed documents once via Vespa's voyage-ai-embedder. - Querying: Use
voyage-4-nano(open-source, runs locally on the Vespa container) via hugging-face-embedder for zero-cost, low-latency queries.
We combine binary embeddings for fast first-phase retrieval with float reranking for accuracy.
Relevant resources:
- Vespa embedding documentation
- Embedding Tradeoffs, Quantified — benchmarks of voyage-4-nano-int8 and other models on Vespa
- Nearest Neighbor Search
![]()
!pip3 install -U pyvespa vespacli
Why Asymmetric Retrieval?¶
Embedding documents and queries with the same API-based model works well, but at high query volumes the cost of embedding every query adds up. Asymmetric retrieval eliminates this cost entirely.
The asymmetric insight¶
- Documents are embedded once at indexing time. Use the best model (
voyage-4-large) for maximum quality. - Queries happen on every search. Use a fast, local model (
voyage-4-nano) with zero API cost and no rate limits.
Example: 10K QPS¶
At 10,000 queries/sec with ~30-token queries, that's ~18M tokens per minute. Even at $0.02 per 1M tokens,
this adds up to **~$31K/month** in embedding costs alone. Running voyage-4-nano locally on the Vespa
container reduces this to $0/month with single-digit ms latency — the model runs as part of the
serving infrastructure you're already paying for.
The voyage-4-nano model from the same Voyage 4 family produces embeddings in the same vector space
as voyage-4-large, making cross-model similarity meaningful.
voyage-4-nano-int8 Quality Benchmarks¶
From Embedding Tradeoffs, Quantified, benchmarked on an AWS c7g.2xlarge instance. The model is 332 MB and supports a 32,768 token context with an embedding latency of 12.6-15.0 ms, running on CPU. It also supports Matryoshka Representation Learning (MRL) for flexible dimensionality.
Define the Vespa Schema¶
We define a Vespa schema with two document fields (id, text) and two synthetic embedding fields
computed at indexing time by the voyage-4-large embedder:
embedding_float: Half-precision (bfloat16) embeddings (2048 dimensions) for accurate reranking. Usespagedattribute to keep data on disk, reducing memory cost.embedding_binary: Binary (int8) embeddings (2048/8 = 256 bytes) for fast hamming-distance retrieval.
from vespa.package import Schema, Document, Field
SCHEMA_NAME = "doc"
FEED_MODEL_ID = "voyage-4-large"
QUERY_MODEL_ID = "voyage-4-nano-int8"
schema = Schema(
name=SCHEMA_NAME,
document=Document(
fields=[
Field(name="id", type="string", indexing=["summary", "attribute"]),
Field(name="text", type="string", indexing=["index", "summary"]),
]
),
)
# Synthetic fields: computed from 'text' at indexing time using the voyage-4-large embedder.
# These are not part of the document type, so is_document_field=False.
schema.add_fields(
Field(
name="embedding_float",
type="tensor<bfloat16>(x[2048])",
indexing=["input text", f"embed {FEED_MODEL_ID}", "attribute"],
attribute=["distance-metric: prenormalized-angular", "paged"],
is_document_field=False,
)
)
schema.add_fields(
Field(
name="embedding_binary",
type="tensor<int8>(x[256])", # 2048 bits / 8 = 256 bytes
indexing=["input text", f"embed {FEED_MODEL_ID}", "attribute"],
attribute=["distance-metric: hamming"],
is_document_field=False,
)
)
Rank Profile: Binary Retrieval with Float Reranking¶
This rank profile implements a two-phase strategy:
- First phase: Hamming distance on binary embeddings. This is extremely fast and scans many candidates cheaply.
- Second phase: Cosine closeness on full float embeddings. This is more accurate and applied only to the top candidates from phase one.
The query inputs (q_float, q_bin) are produced by the local voyage-4-nano model at query time.
The rerank_count controls how many first-phase candidates are rescored in the second phase.
from vespa.package import RankProfile, Function, SecondPhaseRanking
RERANK_COUNT = 2000
schema.add_rank_profile(
RankProfile(
name="binary-with-rerank",
inputs=[
("query(q_float)", "tensor<float>(x[2048])"),
("query(q_bin)", "tensor<int8>(x[256])"),
],
functions=[
Function(
name="binary_closeness",
expression="1 - (distance(field, embedding_binary) / 2048)",
),
Function(
name="float_closeness",
expression="reduce(query(q_float) * attribute(embedding_float), sum, x)",
),
],
first_phase="binary_closeness",
second_phase=SecondPhaseRanking(
expression="float_closeness", rerank_count=RERANK_COUNT
),
summary_features=[
"binary_closeness",
"float_closeness",
],
)
)
Why paged for float embeddings?¶
The embedding_float field uses the paged attribute,
which lets Vespa page attribute data from memory to disk. This is critical for keeping memory costs manageable.
Napkin math — memory per document at 2048 dimensions:
| Representation | Type | Bytes/vector | 1M docs | 10M docs | 100M docs |
|---|---|---|---|---|---|
embedding_float |
bfloat16 (16-bit) |
4,096 B | ~3.8 GB | ~38 GB | ~381 GB |
embedding_binary |
int8 (1-bit packed) |
256 B | ~0.24 GB | ~2.4 GB | ~24 GB |
The float embeddings are 16x larger than the binary ones. Without paged, all float vectors must fit in memory.
At 100M documents that's ~381 GB of RAM just for one field. With paged, the OS kernel manages what's in memory
based on access patterns — only the vectors actually touched during reranking need to be resident.
This works well here because float vectors are only accessed during second-phase reranking, not during
first-phase retrieval. The first phase uses only the compact binary embeddings (always in memory), and
the second phase touches at most rerank-count float vectors per query per content node.
Important: Do not combine
pagedwith HNSW indexing, as HNSW requires random access across the full graph during search, which would cause excessive disk I/O. Here we usepagedsafely becauseembedding_floathas no HNSW index — it's accessed only via direct attribute lookups during reranking.
Why rerank-count matters with paged¶
The rerank-count parameter (set to 2000 above) controls
how many first-phase candidates are re-scored in the second phase per content node. This is the knob that
bounds cost:
- Too low (e.g., 50): Fast, but the cheap binary first-phase may miss relevant documents that float reranking would have rescued. Recall suffers.
- Too high (e.g., 50,000): More float vectors paged in from disk per query, increasing latency and disk I/O. The quality gains diminish quickly — most relevant documents are already in the top few thousand candidates.
- 2000: A reasonable default that balances recall, latency, and disk I/O. At 2000 candidates x 4,096 bytes per vector = ~8 MB of float data accessed per query per node — easily serviceable from the OS page cache for any reasonable query rate.
The combination of paged + bounded rerank-count is what makes this architecture work: you get the storage
efficiency of keeping float vectors on disk, with the performance guarantee that each query only touches a
small, predictable number of them.
Services Configuration¶
We configure two embedder components:
voyage-4-large(voyage-ai-embedder): Calls the Voyage AI API. Used at document indexing time to produce high-quality embeddings. Requires an API key stored in Vespa Cloud's secret store.voyage-4-nano-int8(hugging-face-embedder): Runs locally on the Vespa container as an ONNX model. Used at query time for zero-cost, low-latency embedding. No API key needed.
Batching for throughput¶
The voyage-ai-embedder supports
dynamic batching of concurrent
embedding requests into single API calls. We configure max-size: 20 (up to 20 documents per batch) and
max-delay: 20ms (maximum wait time before sending a partial batch). Since each batch counts as a single
API call, this can reduce the number of calls by up to 20x — making it much easier to stay within the RPM
(Requests Per Minute) limit of your Voyage API key. Combined with the increased document-processing
threadpool (512 threads), this enables high-throughput parallel embedding at index time.
Quantization¶
The voyage-ai-embedder also supports server-side quantization (with values auto, float, int8, or binary).
When set to auto (the default), Vespa infers the appropriate quantization from the destination tensor's
cell type and dimensions — so our tensor<bfloat16> float field and tensor<int8> binary field are
handled automatically. For this notebook we rely on auto quantization, which gives us full-precision
bfloat16 embeddings paged to disk for accurate reranking, and compact binary embeddings in memory for
fast retrieval.
The ServicesConfiguration class below uses pyvespa's type-safe Python API for generating
services.xml.
For a deeper dive into all the configuration options available, see the
advanced configuration notebook.
from vespa.package import ServicesConfiguration
from vespa.configuration.services import (
services,
batching,
container,
content,
search,
document_api,
document_processing,
component,
components,
model,
api_key_secret_ref,
dimensions,
documents,
document,
nodes,
node,
resources,
secrets,
threadpool,
threads,
redundancy,
transformer_model,
tokenizer_model,
pooling_strategy,
normalize,
prepend,
max_tokens,
query,
)
from vespa.configuration.vt import vt
APPLICATION_NAME = "voyageai"
# Replace with your Vespa Cloud secret store vault and secret name
SECRET_STORE_VAULT_NAME = "pyvespa-testvault"
VOYAGE_SECRET_NAME = "voyage_api_key"
services_config = ServicesConfiguration(
application_name=APPLICATION_NAME,
services_config=services(
container(id=f"{APPLICATION_NAME}_container", version="1.0")(
secrets(
vt(
tag="apiKey",
vault=SECRET_STORE_VAULT_NAME,
name=VOYAGE_SECRET_NAME,
)
),
search(),
document_api(),
# 256 threads per vCPU = 512 total with 2 vCPUs
document_processing(threadpool(threads("256"))),
components(
# Local model for query-time embedding (zero API cost)
component(id="voyage-4-nano-int8", type_="hugging-face-embedder")(
transformer_model(model_id="voyage-4-nano-int8"),
tokenizer_model(model_id="voyage-4-nano-vocab"),
max_tokens("32768"),
pooling_strategy("mean"),
normalize("true"),
prepend(
query(
"Represent the query for retrieving supporting documents: "
)
),
),
# API-based model for index-time embedding (highest quality)
component(id="voyage-4-large", type_="voyage-ai-embedder")(
model("voyage-4-large"),
api_key_secret_ref("apiKey"),
dimensions("2048"),
batching(max_size="20", max_delay="20ms"),
),
),
nodes(count="1", required="true")(
resources(vcpu="2", memory="8Gb", disk="50Gb", architecture="arm64")
),
),
content(id=f"{APPLICATION_NAME}_content", version="1.0")(
redundancy("1"),
documents(document(type_="doc", mode="index")),
nodes(node(distribution_key="0", hostalias="node1")),
),
),
)
Create and Deploy the Application Package¶
from vespa.package import ApplicationPackage
app_package = ApplicationPackage(
name=APPLICATION_NAME,
schema=[schema],
services_config=services_config,
)
Deploy to Vespa Cloud. Create a tenant at console.vespa-cloud.com if you don't have one.
Before deploying, you need to configure a secret in the Vespa Cloud secret store with your Voyage AI API key. See Vespa Cloud secret store for instructions.
Deployments to dev expire after 14 days of inactivity.
from vespa.deployment import VespaCloud
from vespa.application import Vespa
import os
tenant_name = "vespa-team" # Replace with your tenant name
key = os.getenv("VESPA_TEAM_API_KEY", None)
if key is not None:
key = key.replace(r"\n", "\n")
vespa_cloud = VespaCloud(
tenant=tenant_name,
application=APPLICATION_NAME,
# key_content=key,
application_package=app_package,
)
app: Vespa = vespa_cloud.deploy()
Setting application...
Running: vespa config set application vespa-team.voyageai.default
Setting target cloud...
Running: vespa config set target cloud
No api-key found for control plane access. Using access token.
Checking for access token in auth.json...
Access token expired. Please re-authenticate.
Your Device Confirmation code is: RWHK-VXWW
Automatically open confirmation page in your default browser? [Y/n] y
Opened link in your browser:
https://login.console.vespa-cloud.com/activate?user_code=RWHK-VXWW
Waiting for login to complete in browser ... done;1m⣻
Success: Logged in
auth.json created at /Users/thomas/.vespa/auth.json
Successfully obtained access token for control plane access.
Deployment started in run 9 of dev-aws-us-east-1c for vespa-team.voyageai. This may take a few minutes the first time.
INFO [13:26:31] Deploying platform version 8.649.29 and application dev build 9 for dev-aws-us-east-1c of default ...
INFO [13:26:31] Using CA signed certificate version 1
INFO [13:26:37] Session 404822 for tenant 'vespa-team' prepared and activated.
INFO [13:27:04] ######## Details for all nodes ########
INFO [13:27:04] h136163a.dev.us-east-1c.aws.vespa-cloud.net: expected to be UP
INFO [13:27:04] --- platform vespa/cloud-tenant-rhel8:8.649.29
INFO [13:27:04] --- logserver-container on port 4080 has not started
INFO [13:27:04] --- metricsproxy-container on port 19092 has not started
INFO [13:27:04] h136163b.dev.us-east-1c.aws.vespa-cloud.net: expected to be UP
INFO [13:27:04] --- platform vespa/cloud-tenant-rhel8:8.649.29
INFO [13:27:04] --- container-clustercontroller on port 19050 has not started
INFO [13:27:04] --- metricsproxy-container on port 19092 has not started
INFO [13:27:04] h136175a.dev.us-east-1c.aws.vespa-cloud.net: expected to be UP
INFO [13:27:04] --- platform vespa/cloud-tenant-rhel8:8.649.29
INFO [13:27:04] --- container on port 4080 has not started
INFO [13:27:04] --- metricsproxy-container on port 19092 has not started
INFO [13:27:04] h136066a.dev.us-east-1c.aws.vespa-cloud.net: expected to be UP
INFO [13:27:04] --- platform vespa/cloud-tenant-rhel8:8.649.29
INFO [13:27:04] --- storagenode on port 19102 has not started
INFO [13:27:04] --- searchnode on port 19107 has not started
INFO [13:27:04] --- distributor on port 19111 has not started
INFO [13:27:04] --- metricsproxy-container on port 19092 has not started
INFO [13:28:01] Waiting for convergence of 10 services across 4 nodes
INFO [13:28:01] 1 nodes booting
INFO [13:28:01] 1 application services still deploying
DEBUG [13:28:01] h136175a.dev.us-east-1c.aws.vespa-cloud.net: expected to be UP
DEBUG [13:28:01] --- platform vespa/cloud-tenant-rhel8:8.649.29
DEBUG [13:28:01] --- container on port 4080 has not started
DEBUG [13:28:01] --- metricsproxy-container on port 19092 has config generation 404822, wanted is 404822
INFO [13:28:43] Found endpoints:
INFO [13:28:43] - dev.aws-us-east-1c
INFO [13:28:43] |-- https://ca603d84.b347094a.z.vespa-app.cloud/ (cluster 'voyageai_container')
INFO [13:28:43] Deployment complete!
Only region: aws-us-east-1c available in dev environment.
Found mtls endpoint for voyageai_container
URL: https://ca603d84.b347094a.z.vespa-app.cloud/
Application is up!
Feed Sample Documents¶
We feed a few sample passages. At indexing time, Vespa calls the voyage-4-large API
to generate both the float and binary embedding representations.
from vespa.io import VespaResponse
sample_docs = [
{
"id": "1",
"fields": {
"id": "1",
"text": "Retrieval-augmented generation (RAG) combines a retrieval system with a generative language model. The retriever finds relevant passages from a corpus, and the generator uses them as context to produce accurate, grounded answers.",
},
},
{
"id": "2",
"fields": {
"id": "2",
"text": "Binary quantization reduces embedding storage by representing each dimension as a single bit. While this loses precision, combining binary retrieval with float reranking recovers most of the accuracy at a fraction of the memory cost.",
},
},
{
"id": "3",
"fields": {
"id": "3",
"text": "Vespa is a fully featured search engine and vector database. It supports real-time indexing, structured and unstructured data, and advanced ranking with multiple retrieval and ranking phases.",
},
},
{
"id": "4",
"fields": {
"id": "4",
"text": "Asymmetric retrieval uses different models for documents and queries. Documents are embedded once with an expensive, high-quality model, while queries use a smaller, faster model to keep latency low and costs down.",
},
},
{
"id": "5",
"fields": {
"id": "5",
"text": "The Voyage 4 embedding model family includes voyage-4-large for maximum quality, voyage-4-lite for a balance of cost and quality, and voyage-4-nano as a small open-source model suitable for local deployment.",
},
},
]
for doc in sample_docs:
response: VespaResponse = app.feed_data_point(
schema=SCHEMA_NAME, data_id=doc["id"], fields=doc["fields"]
)
assert (
response.is_successful()
), f"Failed to feed doc {doc['id']}: {response.get_json()}"
print(f"Fed document {doc['id']}")
Fed document 1 Fed document 2 Fed document 3 Fed document 4 Fed document 5
Query with Binary Retrieval and Float Reranking¶
At query time, Vespa uses the local voyage-4-nano model to embed the query text.
The embed() function in the query invokes the local embedder, producing both
float and binary query representations.
The retrieval pipeline:
nearestNeighboronembedding_binaryscans candidates using fast hamming distance.- First-phase ranking scores by
binary_closeness. - Second-phase reranking scores the top candidates by
float_closeness.
from vespa.io import VespaQueryResponse
import vespa.querybuilder as qb
import json
query_text = "How does asymmetric embedding retrieval work?"
response: VespaQueryResponse = app.query(
yql=str(
qb.select("*")
.from_(SCHEMA_NAME)
.where(
qb.nearestNeighbor(
field="embedding_binary",
query_vector="q_bin",
annotations={"targetHits": 100},
)
)
),
ranking="binary-with-rerank",
body={
"input.query(q_bin)": f'embed({QUERY_MODEL_ID}, "{query_text}")',
"input.query(q_float)": f'embed({QUERY_MODEL_ID}, "{query_text}")',
"hits": 5,
"presentation.timing": "true",
},
)
assert response.is_successful()
for hit in response.hits:
print(json.dumps(hit, indent=2))
{
"fields": {
"documentid": "id:doc:doc::4",
"id": "4",
"sddocname": "doc",
"summaryfeatures": {
"binary_closeness": 0.63623046875,
"float_closeness": 0.5481828630707257,
"vespa.summaryFeatures.cached": 0.0
},
"text": "Asymmetric retrieval uses different models for documents and queries. Documents are embedded once with an expensive, high-quality model, while queries use a smaller, faster model to keep latency low and costs down."
},
"id": "id:doc:doc::4",
"relevance": 0.5481828630707257,
"source": "voyageai_content"
}
{
"fields": {
"documentid": "id:doc:doc::2",
"id": "2",
"sddocname": "doc",
"summaryfeatures": {
"binary_closeness": 0.607421875,
"float_closeness": 0.44831951343722665,
"vespa.summaryFeatures.cached": 0.0
},
"text": "Binary quantization reduces embedding storage by representing each dimension as a single bit. While this loses precision, combining binary retrieval with float reranking recovers most of the accuracy at a fraction of the memory cost."
},
"id": "id:doc:doc::2",
"relevance": 0.44831951343722665,
"source": "voyageai_content"
}
{
"fields": {
"documentid": "id:doc:doc::1",
"id": "1",
"sddocname": "doc",
"summaryfeatures": {
"binary_closeness": 0.58837890625,
"float_closeness": 0.34075708348829004,
"vespa.summaryFeatures.cached": 0.0
},
"text": "Retrieval-augmented generation (RAG) combines a retrieval system with a generative language model. The retriever finds relevant passages from a corpus, and the generator uses them as context to produce accurate, grounded answers."
},
"id": "id:doc:doc::1",
"relevance": 0.34075708348829004,
"source": "voyageai_content"
}
{
"fields": {
"documentid": "id:doc:doc::5",
"id": "5",
"sddocname": "doc",
"summaryfeatures": {
"binary_closeness": 0.58154296875,
"float_closeness": 0.31555799518827143,
"vespa.summaryFeatures.cached": 0.0
},
"text": "The Voyage 4 embedding model family includes voyage-4-large for maximum quality, voyage-4-lite for a balance of cost and quality, and voyage-4-nano as a small open-source model suitable for local deployment."
},
"id": "id:doc:doc::5",
"relevance": 0.31555799518827143,
"source": "voyageai_content"
}
{
"fields": {
"documentid": "id:doc:doc::3",
"id": "3",
"sddocname": "doc",
"summaryfeatures": {
"binary_closeness": 0.5703125,
"float_closeness": 0.29142659282264916,
"vespa.summaryFeatures.cached": 0.0
},
"text": "Vespa is a fully featured search engine and vector database. It supports real-time indexing, structured and unstructured data, and advanced ranking with multiple retrieval and ranking phases."
},
"id": "id:doc:doc::3",
"relevance": 0.29142659282264916,
"source": "voyageai_content"
}
The summaryfeatures in each hit show both scoring phases:
binary_closeness: The first-phase hamming-based score (fast, approximate).float_closeness: The second-phase dot-product score between the query and document float embeddings. Since both embeddings are unit-normalized (prenormalized-angular), the dot product equals cosine similarity.
The final relevance score is the second-phase float closeness for reranked candidates.
response.json["timing"]
{'querytime': 0.032,
'searchtime': 0.051000000000000004,
'summaryfetchtime': 0.015}
Cleanup¶
vespa_cloud.delete()