Chat with your pdfs with ColBERT, langchain, and Vespa¶
This notebook illustrates using Vespa streaming mode to build cost-efficient RAG applications over naturally sharded data. It also demonstrates how you can now use ColBERT ranking natively in Vespa, which can now handle the ColBERT embedding process for you with no custom code!
You can read more about Vespa vector streaming search in these blog posts:
- Announcing vector streaming search: AI assistants at scale without breaking the bank
- Yahoo Mail turns to Vespa to do RAG at scale
- Hands-On RAG guide for personal data with Vespa and LLamaIndex
- Turbocharge RAG with LangChain and Vespa Streaming Mode for Sharded Data
TLDR; Vespa streaming mode for partitioned data¶
Vespa's streaming search solution enables you to integrate a user ID (or any sharding key) into the Vespa document ID. This setup allows Vespa to efficiently group each user's data on a small set of nodes and the same disk chunk. Streaming mode enables low latency searches on a user's data without keeping data in memory.
The key benefits of streaming mode:
- Eliminating compromises in precision introduced by approximate algorithms
- Achieve significantly higher write throughput, thanks to the absence of index builds required for supporting approximate search.
- Optimize efficiency by storing documents, including tensors and data, on disk, benefiting from the cost-effective economics of storage tiers.
- Storage cost is the primary cost driver of Vespa streaming mode; no data is in memory. Avoiding memory usage lowers deployment costs significantly.
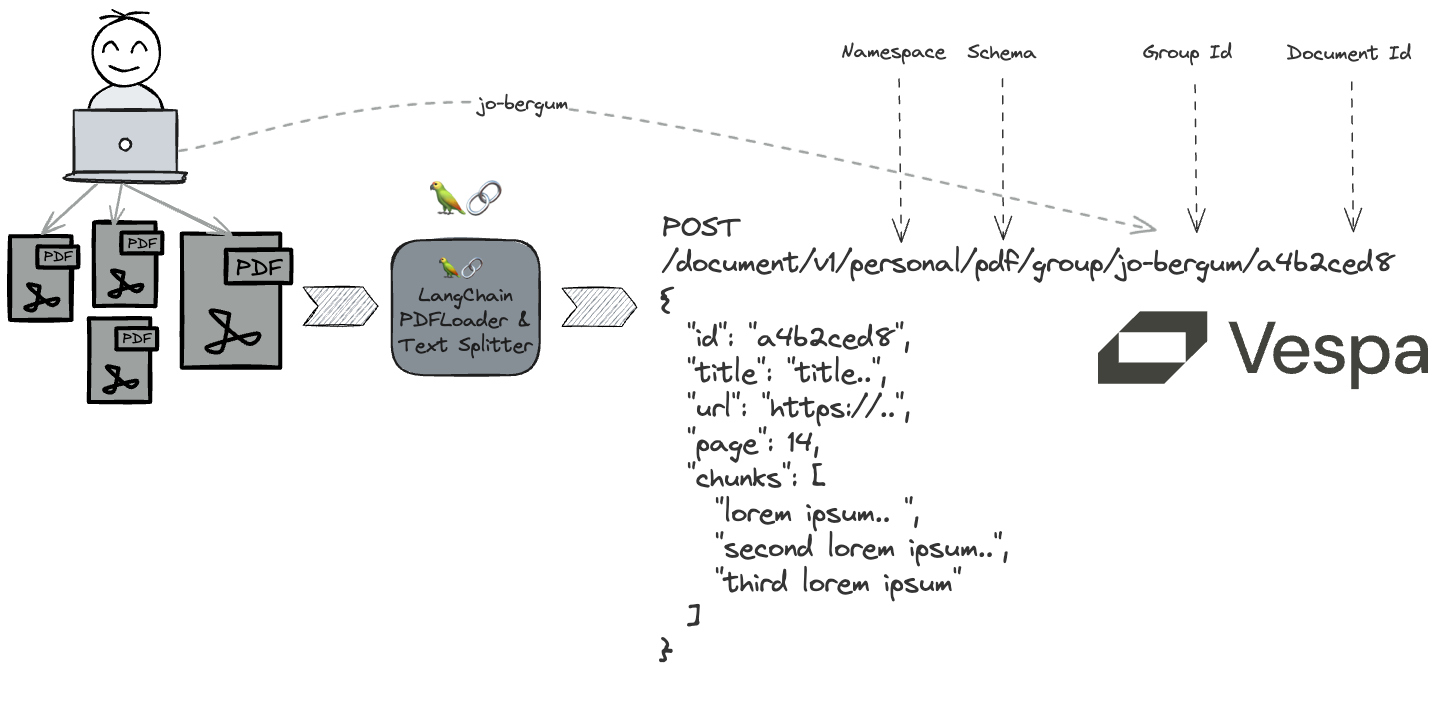
Connecting LangChain Retriever with Vespa for Context Retrieval from PDF Documents¶
In this notebook, we seamlessly integrate a custom LangChain retriever with a Vespa app, leveraging Vespa's streaming mode to extract meaningful context from PDF documents.
The workflow
- Define and deploy a Vespa application package using PyVespa.
- Utilize LangChain PDF Loaders to download and parse PDF files.
- Leverage LangChain Document Transformers to convert each PDF page into multiple model context-sized parts.
- Feed the transformer representation to the running Vespa instance
- Employ Vespa's built-in ColBERT embedder functionality (using an open-source embedding model) for embedding the contexts, resulting in a multi-vector representation per context
- Develop a custom Retriever to enable seamless retrieval for any unstructured text query.
![]()
Let's get started! First, install dependencies:
!uv pip install -q pyvespa langchain langchain-community langchain-openai langchain-text-splitters pypdf==5.0.1 openai vespacli
def sample_pdfs():
return [
{
"title": "ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction",
"url": "https://arxiv.org/pdf/2112.01488.pdf",
"authors": "Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, Matei Zaharia",
},
{
"title": "ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT",
"url": "https://arxiv.org/pdf/2004.12832.pdf",
"authors": "Omar Khattab, Matei Zaharia",
},
{
"title": "On Approximate Nearest Neighbour Selection for Multi-Stage Dense Retrieval",
"url": "https://arxiv.org/pdf/2108.11480.pdf",
"authors": "Craig Macdonald, Nicola Tonellotto",
},
{
"title": "A Study on Token Pruning for ColBERT",
"url": "https://arxiv.org/pdf/2112.06540.pdf",
"authors": "Carlos Lassance, Maroua Maachou, Joohee Park, Stéphane Clinchant",
},
{
"title": "Pseudo-Relevance Feedback for Multiple Representation Dense Retrieval",
"url": "https://arxiv.org/pdf/2106.11251.pdf",
"authors": "Xiao Wang, Craig Macdonald, Nicola Tonellotto, Iadh Ounis",
},
]
Defining the Vespa application¶
PyVespa helps us build the Vespa application package. A Vespa application package consists of configuration files, schemas, models, and code (plugins).
First, we define a Vespa schema with the fields we want to store and their type.
from vespa.package import Schema, Document, Field, FieldSet
pdf_schema = Schema(
name="pdf",
mode="streaming",
document=Document(
fields=[
Field(name="id", type="string", indexing=["summary"]),
Field(name="title", type="string", indexing=["summary", "index"]),
Field(name="url", type="string", indexing=["summary", "index"]),
Field(name="authors", type="array<string>", indexing=["summary", "index"]),
Field(
name="metadata",
type="map<string,string>",
indexing=["summary", "index"],
),
Field(name="page", type="int", indexing=["summary", "attribute"]),
Field(name="contexts", type="array<string>", indexing=["summary", "index"]),
Field(
name="embedding",
type="tensor<bfloat16>(context{}, x[384])",
indexing=[
"input contexts",
'for_each { (input title || "") . " " . ( _ || "") }',
"embed e5",
"attribute",
],
attribute=["distance-metric: angular"],
is_document_field=False,
),
Field(
name="colbert",
type="tensor<int8>(context{}, token{}, v[16])",
indexing=["input contexts", "embed colbert context", "attribute"],
is_document_field=False,
),
],
),
fieldsets=[FieldSet(name="default", fields=["title", "contexts"])],
)
The above defines our pdf schema using mode streaming. Most fields are straightforward, but take a note of:
metadatausingmap<string,string>- here we can store and match over page level metadata extracted by the PDF parser.contextsusingarray<string>, these are the context-sized text parts that we use langchain document transformers for.- The
embeddingfield of typetensor<bfloat16>(context{},x[384])allows us to store and search the 384-dimensional embeddings per context in the same document - The
colbertfield of typetensor<int8>(context{}, token{}, v[16])stores the ColBERT embeddings, retaining a (quantized) per-token representation of the text.
The observant reader might have noticed the e5 and colbert arguments to the embed expression in the above embedding field.
The e5 argument references a component of the type hugging-face-embedder, and colbert references the new cobert-embedder. We configure
the application package and its name with the pdf schema and the e5 and colbert embedder components.
from vespa.package import ApplicationPackage, Component, Parameter
vespa_app_name = "pdfs"
vespa_application_package = ApplicationPackage(
name=vespa_app_name,
schema=[pdf_schema],
components=[
Component(
id="e5",
type="hugging-face-embedder",
parameters=[
Parameter(
name="transformer-model",
args={
"url": "https://huggingface.co/intfloat/e5-small-v2/resolve/main/model.onnx"
},
),
Parameter(
name="tokenizer-model",
args={
"url": "https://huggingface.co/intfloat/e5-small-v2/raw/main/tokenizer.json"
},
),
Parameter(
name="prepend",
args={},
children=[
Parameter(name="query", args={}, children="query: "),
Parameter(name="document", args={}, children="passage: "),
],
),
],
),
Component(
id="colbert",
type="colbert-embedder",
parameters=[
Parameter(
name="transformer-model",
args={
"url": "https://huggingface.co/colbert-ir/colbertv2.0/resolve/main/model.onnx"
},
),
Parameter(
name="tokenizer-model",
args={
"url": "https://huggingface.co/colbert-ir/colbertv2.0/raw/main/tokenizer.json"
},
),
],
),
],
)
In the last step, we configure ranking by adding rank-profile's to the schema.
Vespa supports phased ranking and has a rich set of built-in rank-features, including many text-matching features such as:
- BM25.
- nativeRank and many more.
Users can also define custom functions using ranking expressions. The following defines a colbert Vespa ranking profile which uses the e5 embedding in the first phase, and the max_sim function in the second phase. The max_sim function performs the late interaction for the ColBERT ranking, and is by default applied to the top 100 documents from the first phase.
from vespa.package import RankProfile, Function, FirstPhaseRanking, SecondPhaseRanking
colbert = RankProfile(
name="colbert",
inputs=[
("query(q)", "tensor<float>(x[384])"),
("query(qt)", "tensor<float>(querytoken{}, v[128])"),
],
functions=[
Function(name="cos_sim", expression="closeness(field, embedding)"),
Function(
name="max_sim_per_context",
expression="""
sum(
reduce(
sum(
query(qt) * unpack_bits(attribute(colbert)) , v
),
max, token
),
querytoken
)
""",
),
Function(
name="max_sim", expression="reduce(max_sim_per_context, max, context)"
),
],
first_phase=FirstPhaseRanking(expression="cos_sim"),
second_phase=SecondPhaseRanking(expression="max_sim"),
match_features=["cos_sim", "max_sim", "max_sim_per_context"],
)
pdf_schema.add_rank_profile(colbert)
Using match-features, Vespa
returns selected features along with the highest scoring documents. Here, we include max_sim_per_context which we can later use to select the top N scoring contexts for each page.
For an example of a hybrid rank-profile which combines semantic search with traditional text retrieval such as BM25, see the previous blog post: Turbocharge RAG with LangChain and Vespa Streaming Mode for Sharded Data
Deploy the application to Vespa Cloud¶
With the configured application, we can deploy it to Vespa Cloud.
To deploy the application to Vespa Cloud we need to create a tenant in the Vespa Cloud:
Create a tenant at console.vespa-cloud.com (unless you already have one). This step requires a Google or GitHub account, and will start your free trial.
Make note of the tenant name, it is used in the next steps.
Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.
from vespa.deployment import VespaCloud
import os
# Replace with your tenant name from the Vespa Cloud Console
tenant_name = "vespa-team"
# Key is only used for CI/CD. Can be removed if logging in interactively
key = os.getenv("VESPA_TEAM_API_KEY", None)
if key is not None:
key = key.replace(r"\n", "\n") # To parse key correctly
vespa_cloud = VespaCloud(
tenant=tenant_name,
application=vespa_app_name,
key_content=key, # Key is only used for CI/CD. Can be removed if logging in interactively
application_package=vespa_application_package,
)
Now deploy the app to Vespa Cloud dev zone.
The first deployment typically takes 2 minutes until the endpoint is up.
from vespa.application import Vespa
app: Vespa = vespa_cloud.deploy()
Deployment started in run 1 of dev-aws-us-east-1c for vespa-team.pdfs. This may take a few minutes the first time. INFO [19:04:30] Deploying platform version 8.314.57 and application dev build 1 for dev-aws-us-east-1c of default ... INFO [19:04:30] Using CA signed certificate version 1 INFO [19:04:30] Using 1 nodes in container cluster 'pdfs_container' INFO [19:04:35] Session 285265 for tenant 'vespa-team' prepared and activated. INFO [19:04:39] ######## Details for all nodes ######## INFO [19:04:44] h88969d.dev.aws-us-east-1c.vespa-external.aws.oath.cloud: expected to be UP INFO [19:04:44] --- platform vespa/cloud-tenant-rhel8:8.314.57 <-- : INFO [19:04:44] --- container-clustercontroller on port 19050 has not started INFO [19:04:44] --- metricsproxy-container on port 19092 has not started INFO [19:04:44] h88978a.dev.aws-us-east-1c.vespa-external.aws.oath.cloud: expected to be UP INFO [19:04:44] --- platform vespa/cloud-tenant-rhel8:8.314.57 <-- : INFO [19:04:44] --- logserver-container on port 4080 has not started INFO [19:04:44] --- metricsproxy-container on port 19092 has not started INFO [19:04:44] h90615b.dev.aws-us-east-1c.vespa-external.aws.oath.cloud: expected to be UP INFO [19:04:44] --- platform vespa/cloud-tenant-rhel8:8.314.57 <-- : INFO [19:04:44] --- storagenode on port 19102 has not started INFO [19:04:44] --- searchnode on port 19107 has not started INFO [19:04:44] --- distributor on port 19111 has not started INFO [19:04:44] --- metricsproxy-container on port 19092 has not started INFO [19:04:44] h91135a.dev.aws-us-east-1c.vespa-external.aws.oath.cloud: expected to be UP INFO [19:04:44] --- platform vespa/cloud-tenant-rhel8:8.314.57 <-- : INFO [19:04:44] --- container on port 4080 has not started INFO [19:04:44] --- metricsproxy-container on port 19092 has not started INFO [19:05:52] Waiting for convergence of 10 services across 4 nodes INFO [19:05:52] 1/1 nodes upgrading platform INFO [19:05:52] 1 application services still deploying DEBUG [19:05:52] h91135a.dev.aws-us-east-1c.vespa-external.aws.oath.cloud: expected to be UP DEBUG [19:05:52] --- platform vespa/cloud-tenant-rhel8:8.314.57 <-- : DEBUG [19:05:52] --- container on port 4080 has not started DEBUG [19:05:52] --- metricsproxy-container on port 19092 has config generation 285265, wanted is 285265 INFO [19:06:21] Found endpoints: INFO [19:06:21] - dev.aws-us-east-1c INFO [19:06:21] |-- https://bac3e5ad.c81e7b13.z.vespa-app.cloud/ (cluster 'pdfs_container') INFO [19:06:22] Installation succeeded! Using mTLS (key,cert) Authentication against endpoint https://bac3e5ad.c81e7b13.z.vespa-app.cloud//ApplicationStatus Application is up! Finished deployment.
Processing PDFs with LangChain¶
LangChain has a rich set of document loaders that can be used to load and process various file formats. In this notebook, we use the PyPDFLoader.
We also want to split the extracted text into contexts using a text splitter. Most text embedding models have limited input lengths (typically less than 512 language model tokens, so splitting the text into multiple contexts that each fits into the context limit of the embedding model is a common strategy.
For embedding text data, models based on the Transformer architecture have become the de facto standard. A challenge with Transformer-based models is their input length limitation due to the quadratic self-attention computational complexity. For example, a popular open-source text embedding model like e5 has an absolute maximum input length of 512 wordpiece tokens. In addition to the technical limitation, trying to fit more tokens than used during fine-tuning of the model will impact the quality of the vector representation.
One can view this text embedding encoding as a lossy compression technique, where variable-length texts are compressed into a fixed dimensional vector representation.
Although this compressed representation is very useful, it can be imprecise especially as the size of the text increases. By adding the ColBERT embedding, we also retain token-level information which retains more of the original meaning of the text and allows the richer late interaction between the query and the document text.
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1024, # chars, not llm tokens
chunk_overlap=0,
length_function=len,
is_separator_regex=False,
)
The following iterates over the sample_pdfs and performs the following:
- Load the URL and extract the text into pages. A page is the retrievable unit we will use in Vespa
- For each page, use the text splitter to split the text into contexts. The contexts are represented as an
array<string>in the Vespa schema - Create the page level Vespa
fields, note that we duplicate some content like the title and URL into the page level representation.
import hashlib
import unicodedata
def remove_control_characters(s):
return "".join(ch for ch in s if unicodedata.category(ch)[0] != "C")
my_docs_to_feed = []
for pdf in sample_pdfs():
url = pdf["url"]
loader = PyPDFLoader(url)
pages = loader.load_and_split()
for index, page in enumerate(pages):
source = page.metadata["source"]
chunks = text_splitter.transform_documents([page])
text_chunks = [chunk.page_content for chunk in chunks]
text_chunks = [remove_control_characters(chunk) for chunk in text_chunks]
page_number = index + 1
vespa_id = f"{url}#{page_number}"
hash_value = hashlib.sha1(vespa_id.encode()).hexdigest()
fields = {
"title": pdf["title"],
"url": url,
"page": page_number,
"id": hash_value,
"authors": [a.strip() for a in pdf["authors"].split(",")],
"contexts": text_chunks,
"metadata": page.metadata,
}
my_docs_to_feed.append(fields)
Now that we have parsed the input PDFs and created a list of pages that we want to add to Vespa, we must format the
list into the format that PyVespa accepts. Notice the fields, id and groupname keys. The groupname is the
key that is used to shard and co-locate the data and is only relevant when using Vespa with streaming mode.
from typing import Iterable
def vespa_feed(user: str) -> Iterable[dict]:
for doc in my_docs_to_feed:
yield {"fields": doc, "id": doc["id"], "groupname": user}
my_docs_to_feed[0]
{'title': 'ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction',
'url': 'https://arxiv.org/pdf/2112.01488.pdf',
'page': 1,
'id': 'a731a839198de04fa3d1a3cee6890d0d170ab025',
'authors': ['Keshav Santhanam',
'Omar Khattab',
'Jon Saad-Falcon',
'Christopher Potts',
'Matei Zaharia'],
'contexts': ['ColBERTv2:Effective and Efficient Retrieval via Lightweight Late InteractionKeshav Santhanam∗Stanford UniversityOmar Khattab∗Stanford UniversityJon Saad-FalconGeorgia Institute of TechnologyChristopher PottsStanford UniversityMatei ZahariaStanford UniversityAbstractNeural information retrieval (IR) has greatlyadvanced search and other knowledge-intensive language tasks. While many neuralIR methods encode queries and documentsinto single-vector representations, lateinteraction models produce multi-vector repre-sentations at the granularity of each token anddecompose relevance modeling into scalabletoken-level computations. This decompositionhas been shown to make late interaction moreeffective, but it inflates the space footprint ofthese models by an order of magnitude. In thiswork, we introduce ColBERTv2, a retrieverthat couples an aggressive residual compres-sion mechanism with a denoised supervisionstrategy to simultaneously improve the quality',
'and space footprint of late interaction. Weevaluate ColBERTv2 across a wide rangeof benchmarks, establishing state-of-the-artquality within and outside the training domainwhile reducing the space footprint of lateinteraction models by 6–10 ×.1 IntroductionNeural information retrieval (IR) has quickly domi-nated the search landscape over the past 2–3 years,dramatically advancing not only passage and doc-ument search (Nogueira and Cho, 2019) but alsomany knowledge-intensive NLP tasks like open-domain question answering (Guu et al., 2020),multi-hop claim verification (Khattab et al., 2021a),and open-ended generation (Paranjape et al., 2022).Many neural IR methods follow a single-vectorsimilarity paradigm: a pretrained language modelis used to encode each query and each documentinto a single high-dimensional vector, and rele-vance is modeled as a simple dot product betweenboth vectors. An alternative is late interaction , in-troduced in ColBERT (Khattab and Zaharia, 2020),',
'where queries and documents are encoded at a finer-granularity into multi-vector representations, and∗Equal contribution.relevance is estimated using rich yet scalable in-teractions between these two sets of vectors. Col-BERT produces an embedding for every token inthe query (and document) and models relevanceas the sum of maximum similarities between eachquery vector and all vectors in the document.By decomposing relevance modeling into token-level computations, late interaction aims to reducethe burden on the encoder: whereas single-vectormodels must capture complex query–document re-lationships within one dot product, late interactionencodes meaning at the level of tokens and del-egates query–document matching to the interac-tion mechanism. This added expressivity comesat a cost: existing late interaction systems imposean order-of-magnitude larger space footprint thansingle-vector models, as they must store billionsof small vectors for Web-scale collections. Con-',
'sidering this challenge, it might seem more fruit-ful to focus instead on addressing the fragility ofsingle-vector models (Menon et al., 2022) by in-troducing new supervision paradigms for negativemining (Xiong et al., 2020), pretraining (Gao andCallan, 2021), and distillation (Qu et al., 2021).Indeed, recent single-vector models with highly-tuned supervision strategies (Ren et al., 2021b; For-mal et al., 2021a) sometimes perform on-par oreven better than “vanilla” late interaction models,and it is not necessarily clear whether late inter-action architectures—with their fixed token-levelinductive biases—admit similarly large gains fromimproved supervision.In this work, we show that late interaction re-trievers naturally produce lightweight token rep-resentations that are amenable to efficient storageoff-the-shelf and that they can benefit drasticallyfrom denoised supervision. We couple those inColBERTv2 ,1a new late-interaction retriever that'],
'metadata': {'source': 'https://arxiv.org/pdf/2112.01488.pdf', 'page': 0}}
Now, we can feed to the Vespa instance (app), using the feed_iterable API, using the generator function above as input
with a custom callback function. Vespa also performs embedding inference during this step using the built-in Vespa embedding functionality.
from vespa.io import VespaResponse
def callback(response: VespaResponse, id: str):
if not response.is_successful():
print(
f"Document {id} failed to feed with status code {response.status_code}, url={response.url} response={response.json}"
)
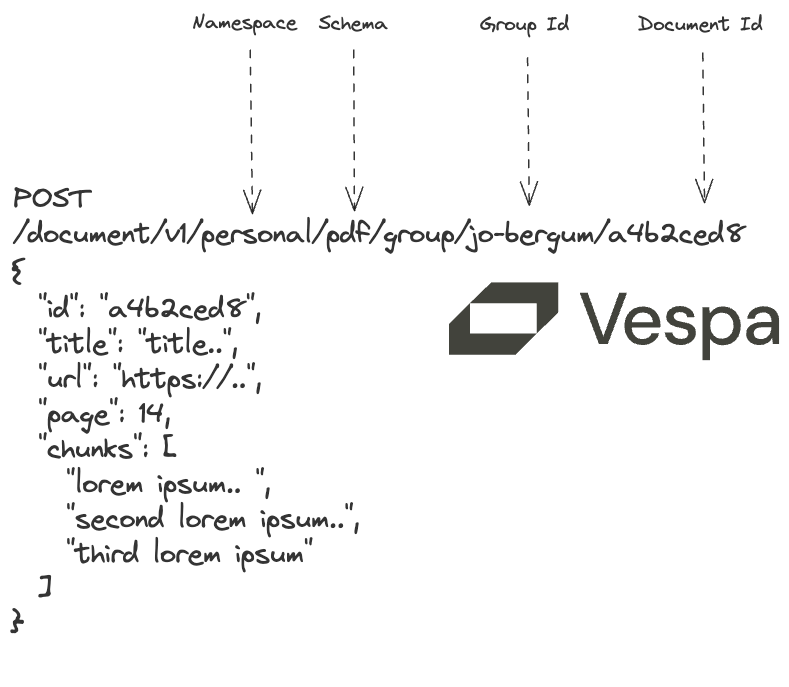
app.feed_iterable(
schema="pdf", iter=vespa_feed("jo-bergum"), namespace="personal", callback=callback
)
Notice the schema and namespace arguments. PyVespa transforms the input operations to Vespa document v1
requests.
Querying data¶
Now, we can also query our data. With streaming mode,
we must pass the groupname parameter, or the request will fail with an error.
The query request uses the Vespa Query API and the Vespa.query() function
supports passing any of the Vespa query API parameters.
Read more about querying Vespa in:
Sample query request for why is colbert effective? for the user jo-bergum:
from vespa.io import VespaQueryResponse
import json
response: VespaQueryResponse = app.query(
yql="select id,title,page,contexts from pdf where ({targetHits:10}nearestNeighbor(embedding,q))",
groupname="jo-bergum",
ranking="colbert",
query="why is colbert effective?",
body={
"presentation.format.tensors": "short-value",
"input.query(q)": 'embed(e5, "why is colbert effective?")',
"input.query(qt)": 'embed(colbert, "why is colbert effective?")',
},
timeout="2s",
)
assert response.is_successful()
print(json.dumps(response.hits[0], indent=2))
{
"id": "id:personal:pdf:g=jo-bergum:55ea3f735cb6748a2eddb9f76d3f0e7fff0c31a8",
"relevance": 103.17699432373047,
"source": "pdfs_content.pdf",
"fields": {
"matchfeatures": {
"cos_sim": 0.6534222205340683,
"max_sim": 103.17699432373047,
"max_sim_per_context": {
"0": 74.16375732421875,
"1": 103.17699432373047
}
},
"id": "55ea3f735cb6748a2eddb9f76d3f0e7fff0c31a8",
"title": "ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT",
"page": 18,
"contexts": [
"at least once. While ColBERT encodes each document with BERTexactly once, existing BERT-based rankers would repeat similarcomputations on possibly hundreds of documents for each query.Se/t_ting Dimension( m) Bytes/Dim Space(GiBs) MRR@10Re-rank Cosine 128 4 286 34.9End-to-end L2 128 2 154 36.0Re-rank L2 128 2 143 34.8Re-rank Cosine 48 4 54 34.4Re-rank Cosine 24 2 27 33.9Table 4: Space Footprint vs MRR@10 (Dev) on MS MARCO.Table 4 reports the space footprint of ColBERT under variousse/t_tings as we reduce the embeddings dimension and/or the bytesper dimension. Interestingly, the most space-e\ufb03cient se/t_ting, thatis, re-ranking with cosine similarity with 24-dimensional vectorsstored as 2-byte /f_loats, is only 1% worse in MRR@10 than the mostspace-consuming one, while the former requires only 27 GiBs torepresent the MS MARCO collection.5 CONCLUSIONSIn this paper, we introduced ColBERT, a novel ranking model thatemploys contextualized late interaction over deep LMs (in particular,",
"BERT) for e\ufb03cient retrieval. By independently encoding queriesand documents into /f_ine-grained representations that interact viacheap and pruning-friendly computations, ColBERT can leveragethe expressiveness of deep LMs while greatly speeding up queryprocessing. In addition, doing so allows using ColBERT for end-to-end neural retrieval directly from a large document collection. Ourresults show that ColBERT is more than 170 \u00d7faster and requires14,000\u00d7fewer FLOPs/query than existing BERT-based models, allwhile only minimally impacting quality and while outperformingevery non-BERT baseline.Acknowledgments. OK was supported by the Eltoukhy FamilyGraduate Fellowship at the Stanford School of Engineering. /T_hisresearch was supported in part by a\ufb03liate members and othersupporters of the Stanford DAWN project\u2014Ant Financial, Facebook,Google, Infosys, NEC, and VMware\u2014as well as Cisco, SAP, and the"
]
}
}
Notice the matchfeatures that returns the configured match-features from the rank-profile, including all the context similarities.
LangChain Retriever¶
We use the LangChain Retriever interface so that we can connect our Vespa app with the flexibility and power of the LangChain LLM framework.
A retriever is an interface that returns documents given an unstructured query. It is more general than a vector store. A retriever does not need to be able to store documents, only to return (or retrieve) them. Vector stores can be used as the backbone of a retriever, but there are other types of retrievers as well.
The retriever interface fits perfectly with Vespa, as Vespa can support a wide range of features and ways to retrieve and
rank content. The following implements a custom retriever VespaStreamingColBERTRetriever that takes the following arguments:
app:VespaThe Vespa application we retrieve from. This could be a Vespa Cloud instance or a local instance, for example running on a laptop.user:strThe user that that we want to retrieve for, this argument maps to the Vespa streaming mode groupname parameterpages:intThe target number of PDF pages we want to retrieve for a given querychunks_per_pageThe is the target number of relevant text chunks that are associated with the pagechunk_similarity_threshold- The chunk similarity threshold, only chunks with a similarity above this threshold
The core idea is to retrieve pages using max context similarity as the initial scoring function, then re-rank the top-K pages using the ColBERT embeddings. This re-ranking is handled by the second phase of the Vespa ranking expression defined above, and is transparent to the retriever code below.
from langchain_core.documents import Document
from langchain_core.retrievers import BaseRetriever
from typing import List
class VespaStreamingColBERTRetriever(BaseRetriever):
app: Vespa
user: str
pages: int = 5
chunks_per_page: int = 3
chunk_similarity_threshold: float = 0.8
def _get_relevant_documents(self, query: str) -> List[Document]:
response: VespaQueryResponse = self.app.query(
yql="select id, url, title, page, authors, contexts from pdf where userQuery() or ({targetHits:20}nearestNeighbor(embedding,q))",
groupname=self.user,
ranking="colbert",
query=query,
hits=self.pages,
body={
"presentation.format.tensors": "short-value",
"input.query(q)": f'embed(e5, "query: {query} ")',
"input.query(qt)": f'embed(colbert, "{query}")',
},
timeout="2s",
)
if not response.is_successful():
raise ValueError(
f"Query failed with status code {response.status_code}, url={response.url} response={response.json}"
)
return self._parse_response(response)
def _parse_response(self, response: VespaQueryResponse) -> List[Document]:
documents: List[Document] = []
for hit in response.hits:
fields = hit["fields"]
chunks_with_scores = self._get_chunk_similarities(fields)
## Best k chunks from each page
best_chunks_on_page = " ### ".join(
[
chunk
for chunk, score in chunks_with_scores[0 : self.chunks_per_page]
if score > self.chunk_similarity_threshold
]
)
documents.append(
Document(
id=fields["id"],
page_content=best_chunks_on_page,
title=fields["title"],
metadata={
"title": fields["title"],
"url": fields["url"],
"page": fields["page"],
"authors": fields["authors"],
"features": fields["matchfeatures"],
},
)
)
return documents
def _get_chunk_similarities(self, hit_fields: dict) -> List[tuple]:
match_features = hit_fields["matchfeatures"]
similarities = match_features["max_sim_per_context"]
chunk_scores = []
for i in range(0, len(similarities)):
chunk_scores.append(similarities.get(str(i), 0))
chunks = hit_fields["contexts"]
chunks_with_scores = list(zip(chunks, chunk_scores))
return sorted(chunks_with_scores, key=lambda x: x[1], reverse=True)
That's it! We can give our newborn retriever a spin for the user jo-bergum by
vespa_hybrid_retriever = VespaStreamingColBERTRetriever(
app=app, user="jo-bergum", pages=1, chunks_per_page=3
)
vespa_hybrid_retriever.invoke("what is the maxsim operator in colbert?")
[Document(page_content='ture that precisely does so. As illustrated, every query embeddinginteracts with all document embeddings via a MaxSim operator,which computes maximum similarity (e.g., cosine similarity), andthe scalar outputs of these operators are summed across queryterms. /T_his paradigm allows ColBERT to exploit deep LM-basedrepresentations while shi/f_ting the cost of encoding documents of-/f_line and amortizing the cost of encoding the query once acrossall ranked documents. Additionally, it enables ColBERT to lever-age vector-similarity search indexes (e.g., [ 1,15]) to retrieve thetop-kresults directly from a large document collection, substan-tially improving recall over models that only re-rank the output ofterm-based retrieval.As Figure 1 illustrates, ColBERT can serve queries in tens orfew hundreds of milliseconds. For instance, when used for re-ranking as in “ColBERT (re-rank)”, it delivers over 170 ×speedup(and requires 14,000 ×fewer FLOPs) relative to existing BERT-based ### models, while being more effective than every non-BERT baseline(§4.2 & 4.3). ColBERT’s indexing—the only time it needs to feeddocuments through BERT—is also practical: it can index the MSMARCO collection of 9M passages in about 3 hours using a singleserver with four GPUs ( §4.5), retaining its effectiveness with a spacefootprint of as li/t_tle as few tens of GiBs. Our extensive ablationstudy ( §4.4) shows that late interaction, its implementation viaMaxSim operations, and crucial design choices within our BERT-based encoders are all essential to ColBERT’s effectiveness.Our main contributions are as follows.(1)We propose late interaction (§3.1) as a paradigm for efficientand effective neural ranking.(2)We present ColBERT ( §3.2 & 3.3), a highly-effective modelthat employs novel BERT-based query and document en-coders within the late interaction paradigm.', metadata={'title': 'ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT', 'url': 'https://arxiv.org/pdf/2004.12832.pdf', 'page': 4, 'authors': ['Omar Khattab', 'Matei Zaharia'], 'features': {'cos_sim': 0.6664045997289173, 'max_sim': 124.19231414794922, 'max_sim_per_context': {'0': 124.19231414794922, '1': 92.21265411376953}}})]
RAG¶
Finally, we can connect our custom retriever with the complete flexibility and power of the [LangChain] LLM framework. The following uses LangChain Expression Language, or LCEL, a declarative way to compose chains.
We have several steps composed into a chain:
- The prompt template and LLM model, in this case using OpenAI
- The retriever that provides the retrieved context for the question
- The formatting of the retrieved context
vespa_hybrid_retriever = VespaStreamingColBERTRetriever(
app=app, user="jo-bergum", chunks_per_page=3
)
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
prompt_template = """
Answer the question based only on the following context.
Cite the page number and the url of the document you are citing.
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(prompt_template)
model = ChatOpenAI(model="gpt-4o")
def format_prompt_context(docs) -> str:
context = []
for d in docs:
context.append(f"{d.metadata['title']} by {d.metadata['authors']}\n")
context.append(f"url: {d.metadata['url']}\n")
context.append(f"page: {d.metadata['page']}\n")
context.append(f"{d.page_content}\n\n")
return "".join(context)
chain = (
{
"context": vespa_hybrid_retriever | format_prompt_context,
"question": RunnablePassthrough(),
}
| prompt
| model
| StrOutputParser()
)
Interact with the chain¶
Now, we can start asking questions using the chain define above.
chain.invoke("what is colbert?")
'ColBERT, introduced by Omar Khattab and Matei Zaharia, is a novel ranking model that employs contextualized late interaction over deep language models (LMs), specifically focusing on BERT (Bidirectional Encoder Representations from Transformers) for efficient and effective passage search. It achieves this by independently encoding queries and documents into fine-grained representations that interact via cheap and pruning-friendly computations. This approach allows ColBERT to leverage the expressiveness of deep LMs while significantly speeding up query processing compared to existing BERT-based models. ColBERT also enables end-to-end neural retrieval directly from a large document collection, offering more than 170 times faster performance and requiring 14,000 times fewer FLOPs (floating-point operations) per query than previous BERT-based models, with minimal impact on quality. It outperforms every non-BERT baseline in effectiveness (https://arxiv.org/pdf/2004.12832.pdf, page 18).\n\nColBERT differentiates itself with a mechanism that delays the query-document interaction, which allows for pre-computation of document representations for cheap neural re-ranking and supports practical end-to-end neural retrieval through pruning via vector-similarity search. This method preserves the effectiveness of state-of-the-art models that condition most of their computations on the joint query-document pair, making ColBERT a scalable solution for passage search challenges (https://arxiv.org/pdf/2004.12832.pdf, page 6).'
chain.invoke("what is the colbert maxsim operator")
'The ColBERT MaxSim operator is a mechanism for computing the maximum similarity between query embeddings and document embeddings. It operates by calculating the maximum similarity (e.g., cosine similarity) for each query embedding with all document embeddings, and then summing the scalar outputs of these operations across query terms. This paradigm enables the efficient and effective retrieval of documents by allowing for the interaction between deep language model-based representations of queries and documents to occur in a late stage of the processing pipeline, thereby shifting the cost of encoding documents offline and amortizing the cost of encoding the query across all ranked documents. Additionally, the MaxSim operator facilitates the use of vector-similarity search indexes to directly retrieve the top-k results from a large document collection, substantially improving recall over models that only re-rank the output of term-based retrieval. This operator is a key component of ColBERT\'s approach to efficient and effective passage search.\n\nSource: "ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT" by Omar Khattab and Matei Zaharia, page 4, https://arxiv.org/pdf/2004.12832.pdf'
chain.invoke(
"What is the difference between colbert and single vector representational models?"
)
'The main difference between ColBERT and single-vector representational models lies in their approach to handling document and query representations for information retrieval tasks. ColBERT utilizes a multi-vector representation for both queries and documents, whereas single-vector models encode each query and each document into a single, dense vector.\n\n1. **Multi-Vector vs. Single-Vector Representations**: ColBERT leverages a late interaction mechanism that allows for fine-grained matching between the multiple embeddings of query terms and document tokens. This approach enables capturing the nuanced semantics of the text by considering the contextualized representation of each term separately. On the other hand, single-vector models compress the entire content of a document or a query into a single dense vector, which might lead to a loss of detail and context specificity.\n\n2. **Efficiency and Effectiveness**: While single-vector models might be simpler and potentially faster in some scenarios due to their straightforward matching mechanism (e.g., cosine similarity between query and document vectors), this simplicity could come at the cost of effectiveness. ColBERT, with its detailed interaction between term-level vectors, can offer more accurate retrieval results because it preserves and utilizes the rich semantic relationships within and across the text of queries and documents. However, ColBERT\'s detailed approach initially required more storage and computational resources compared to single-vector models. Nonetheless, advancements like ColBERTv2 have significantly improved the efficiency, achieving competitive storage requirements and reducing the computational cost while maintaining or even enhancing retrieval effectiveness.\n\n3. **Compression and Storage**: Initial versions of multi-vector models like ColBERT required significantly more storage space compared to single-vector models due to storing multiple vectors per document. However, with the introduction of techniques like residual compression in ColBERTv2, the storage requirements have been drastically reduced to levels competitive with single-vector models. Single-vector models, while naturally more storage-efficient, can also be compressed, but aggressive compression might exacerbate the loss in quality.\n\n4. **Search Quality and Compression**: Despite the potential for aggressive compression in single-vector models, such approaches often lead to a more pronounced loss in quality compared to late interaction methods like ColBERTv2. ColBERTv2, even when employing compression techniques to reduce its storage footprint, can achieve higher quality across systems, showcasing the robustness of its retrieval capabilities even when optimizing for space efficiency.\n\nIn summary, the difference between ColBERT and single-vector representational models is primarily in their approach to encoding and matching queries and documents, with ColBERT focusing on detailed, term-level interactions for improved accuracy, and single-vector models emphasizing simplicity and compactness, which might come at the cost of retrieval effectiveness.\n\nCitations:\n- Santhanam et al., "ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction," p. 14, 15, 17, https://arxiv.org/pdf/2112.01488.pdf'
chain.invoke("Why does ColBERT work better for longer documents?")
"ColBERT is designed to efficiently handle the interaction between query and document representations through a mechanism called late interaction, which is particularly beneficial when dealing with longer documents. This is because ColBERT independently encodes queries and documents into fine-grained representations using BERT, and then employs a cheap yet powerful interaction step that models their fine-grained similarity. This approach allows for the pre-computation of document representations offline, significantly speeding up query processing by avoiding the need to feed each query-document pair through a massive neural network at query time.\n\nFor longer documents, the benefits of this approach are twofold:\n\n1. **Efficiency in Handling Long Documents**: Since ColBERT encodes document representations offline, it can efficiently manage longer documents without a proportional increase in computational cost at query time. This is unlike traditional BERT-based models that might require more computational resources to process longer documents due to their size and complexity.\n\n2. **Effectiveness in Capturing Fine-Grained Semantics**: The fine-grained representations and the late interaction mechanism enable ColBERT to effectively capture the nuances and detailed semantics of longer documents. This is crucial for maintaining high retrieval quality, as longer documents often contain more information and require a more nuanced understanding to match relevant queries accurately.\n\nThus, ColBERT's architecture, which leverages the strengths of BERT for deep language understanding while introducing efficiencies through late interaction, makes it particularly adept at handling longer documents. It achieves this by pre-computing and efficiently utilizing detailed semantic representations of documents, enabling both high-quality retrieval and significant speed-ups in query processing times compared to traditional BERT-based models.\n\nReference: ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT by ['Omar Khattab', 'Matei Zaharia'] (https://arxiv.org/pdf/2004.12832.pdf), page 4."
Summary¶
Vespa’s streaming mode is a game-changer, enabling the creation of highly cost-effective RAG applications for naturally partitioned data. Now it is also possible to use ColBERT for re-ranking, without having to integrate any custom embedder or re-ranking code.
In this notebook, we delved into the hands-on application of LangChain, leveraging document loaders and transformers. Finally, we showcased a custom LangChain retriever that connected all the functionality of LangChain with Vespa.
For those interested in learning more about Vespa, join the Vespa community on Slack to exchange ideas, seek assistance, or stay in the loop on the latest Vespa developments.
We can now delete the cloud instance:
vespa_cloud.delete()